
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- chapter02
- 인공지능
- 5397번
- bisection
- 알고리즘
- 선형분류
- undirected graphical model
- 선형판별분석
- chapter01
- 델타 rule
- vector미분
- CH01
- 1차예선
- 2018
- directed graphical model
- 개발순서
- 자바ORM표준JPA프로그래밍
- MySQL
- graphical models
- 스터디
- Numerical optimization
- secant
- SCPC
- 로지스틱 회귀
- Fisher discriminant analysis
- 근구하기
- 이것이 MySQL이다
- Perceptron Convergence theorem
- 알고리즘대회
- falsePosition
- Today
- Total
computer_study
[인공지능] Graphical models 본문
Graphical models이란?
확률분포를 좀 더 쉽게 해석하기 위한 그래프 도식 방법이다.
장점
- 확률 모델의 구조를 쉽게 시각화 하여 새로운 모델을 디자인하는데 도움을 준다
- 그래프화된 구조를 분석함으로써 모델 숙성에 대한 직관을 얻을 수 있다.
- 복잡한 학습과 추론 과정을 가지는 모델의 계산 과정을 그래픽적인 요소로 표현이 가능하다.
그래프는 node와 edge로 표현되는데, 확률 그래프 모델에서 node는 random variable을 의미하고, link(edge)는 random variable사이의 확률적인 관계를 나타낸다.
이런 Graphical model은 Directed graphical model 혹은 Undirected graphical model 중 하나이다.
motivation
p(x)가 joint density function이라 할 때, chain rule에 의해 다양하게 decompose할 수 있다.


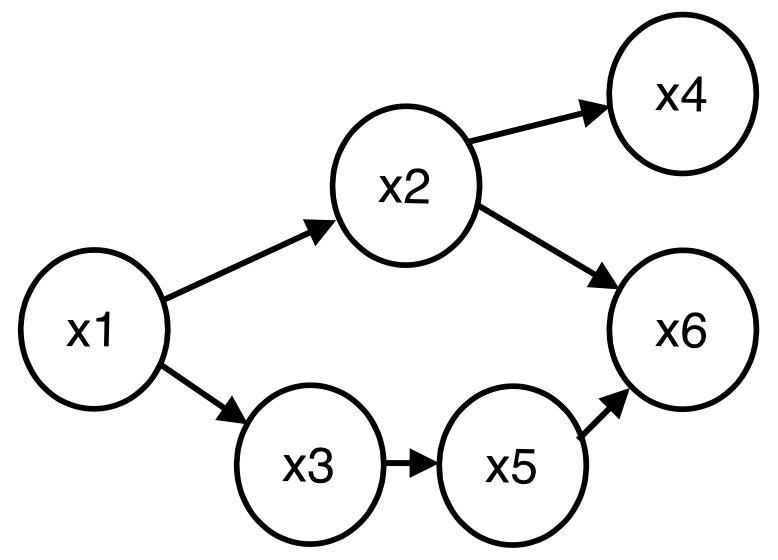
Directed graphical model
graphical model 중 방향성이 있는 model을 말한다.
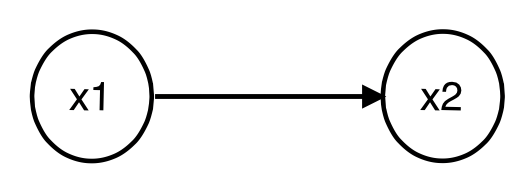
위 그림과 같은 그래프가 주어진다면 이는 다음 식을 만족한다.
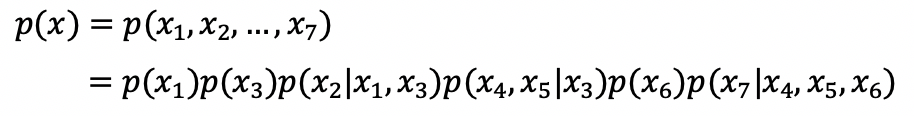
특징
- loop가 존재해선 안된다.
- 이런 특징 때문에 Directed Acyclid graphical model (DAG)-방향성 비순환 그래픽 모델 이라고 부른다.
D-separation
conditional independence(조건부 독립)문제를 다루기 위한 frame work이다.
다양한 그래프에서 나올 수 있는 dependence를 3가지 종류로 구분하였다.
- serial connections
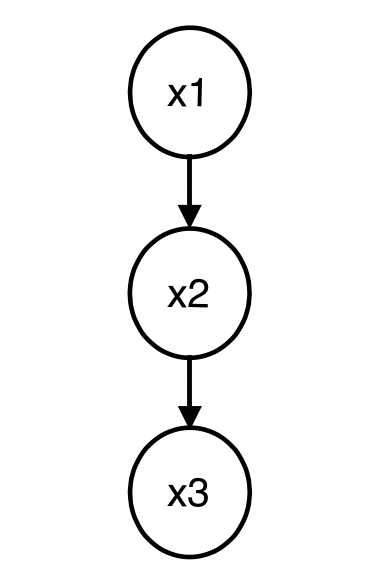
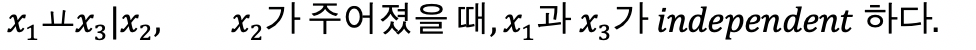
x2가 주어졌을 때, x1과 x3가 independent하다는 의미는, x2가 주어진 x2값일 때의 데이터만을 봤을 때, x1과 x3가 독립이 된다는 얘기이다.
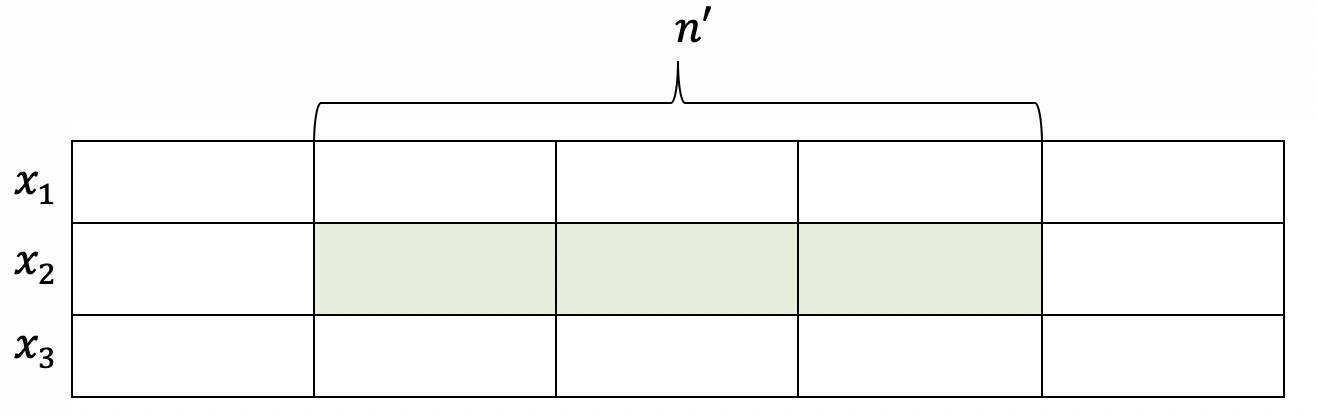
- Diverging connection
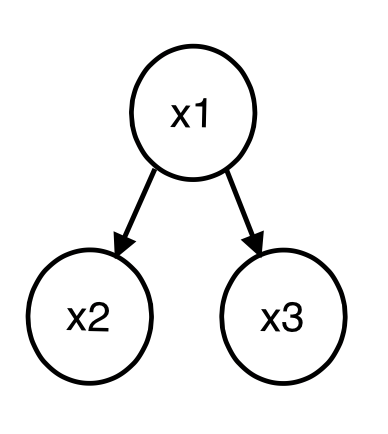
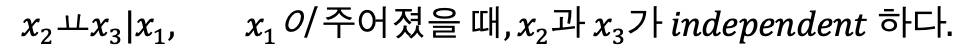
- converging connections
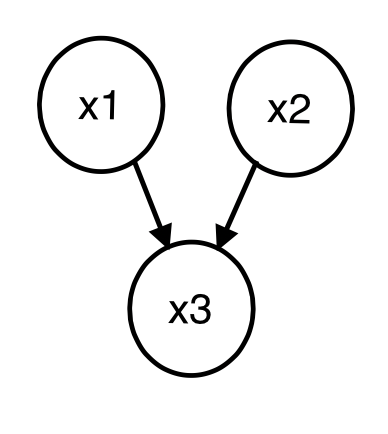

즉, x3가 특정한 값으로 고정되면, x1과 x2관계가 생긴다는 것이다.
D-separation을 이용하면, 위 그림(1)을 다음과 같이 표현할 수도 있다.

Independency 의미
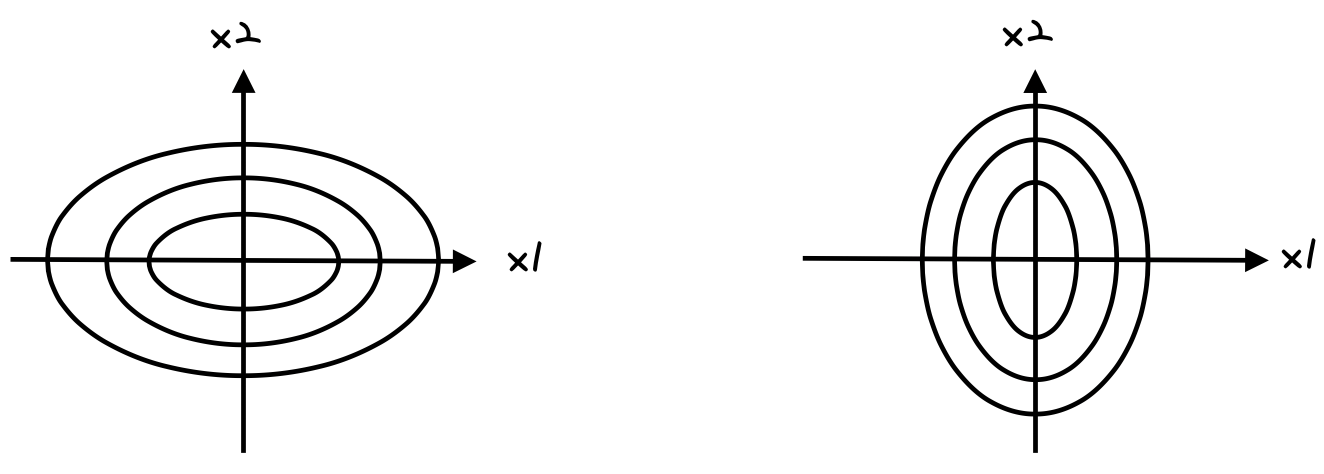
joint probability p(x)가 위와같은 그림이 나와야 x1과 x2가 independent하다는 의미가 된다.
p(x2|x1=somthing) 일 때, x1이 어떤 값이 되더라도 평균값은 항상 같은 probability를 가지기 때문에 x1과 x2는 독립으로 볼 수 있다. (x1 값이 어떤 값이던 x2의 값은 상관이 없다는 의미)
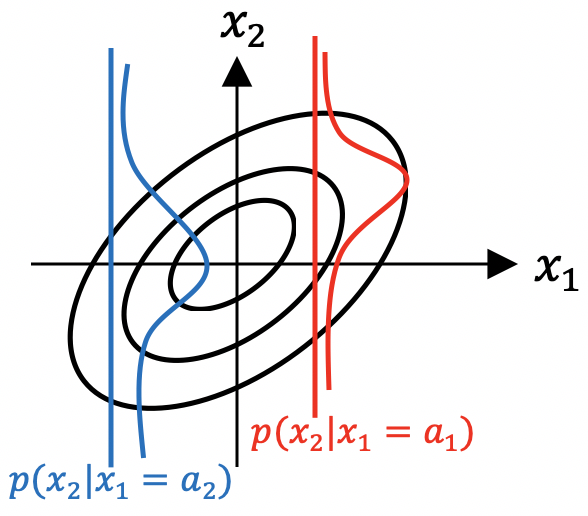
반면 joint probability가 위 그림과 같이 생겼다면, x1의 값에 따라 x2의 값이 변화하기 때문에, 서로 독립이 아니라고 볼 수 있다.
Conditional Independency
conditional independent 하다고 independent 한 것은 아니다.
(p(x1, x2|x3) = p(x1|x3)p(x2|x3) 이라고 해서, p(x1,x2)=p(x1)p(x2)가 되는 것이 아니다.)
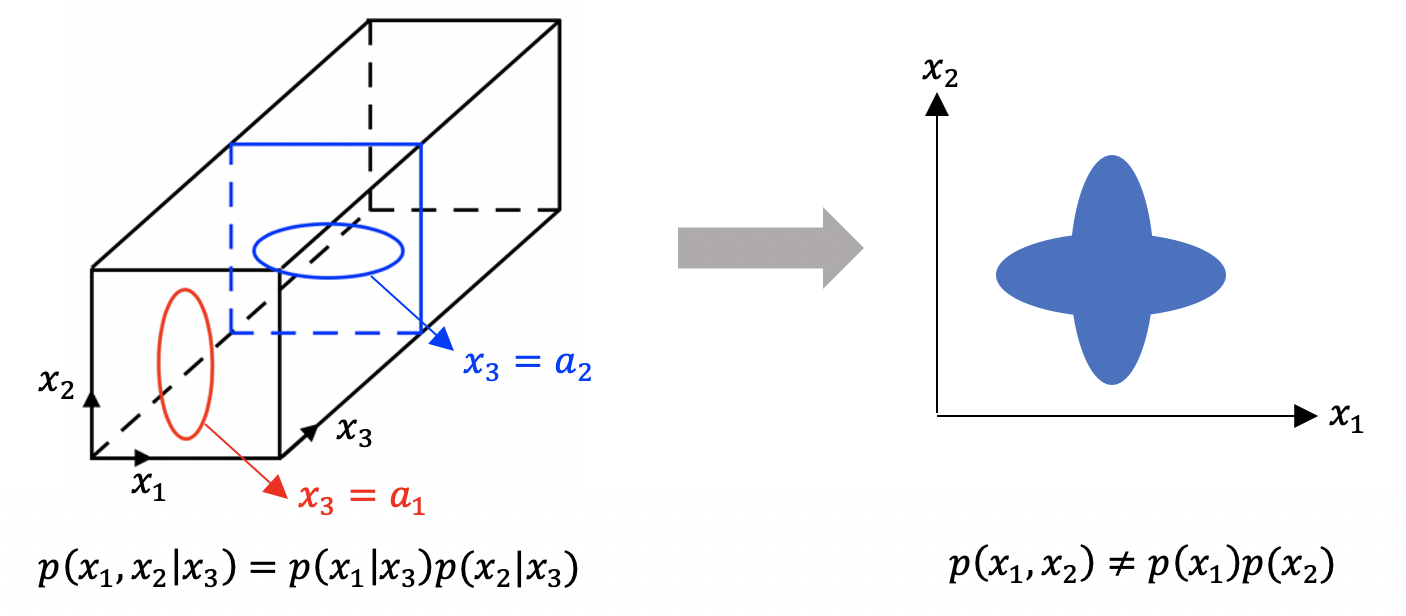
directed graphic model과 관련된 Naive Bayes model
Naive Bayes model을 graphical model로 이해할 수 있다. Naive Bayes model은 다음과 같다.
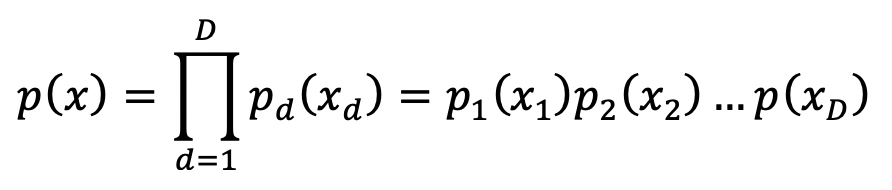
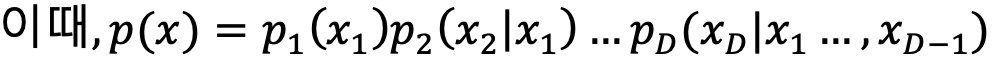
따라서 p2(x2) = p2(x2|x1) 등 모든 항이 같게 되고, 모든 입력변수 x1, x2 ,...xD가 서로 독립적이라는 것을 알 수 있다.
이는 Naive Bayes model을 사용하기 위한 가장 중요한 가정이다. (입력변수가 독립적인 상태로 Naive Bayes model을 사용해야 된다.)
이런 성질 때문에, p(x)가 가우시안 이라면, p1(x1), p2(x2) .. pD(xD) 모두 가우시안 형태가 된다.
- 장점
Naive bayes model을 사용하면, 모든 parameter가 independent 하다는 가정이 있다. 때문에 일반적이라면, 가우시안을 사용했을 때 D2개의 parameter가 필요하지만 Naive nayes model을 사용해서 2D개의 parameter로 parameter수를 대폭 줄일 수 있다.
이러한 성질 때문에 입력 공간의 차원이 높을 때 매우 유리하다.
example

(knowable.tistory.com/51"conditional probability density function"에 p(x2|x1)을 얻어내는 과정을 정리해두었다.)
이렇게 decompose 후에 각 요소들을 구해주면 27개의 parameter를 모두 estimate하지 않고 총 19개의 parameter만 estimate해도 된다.
- 실제 데이터가 주어졌을 때 학습 방법

Undirected graphical model(Markov random field)
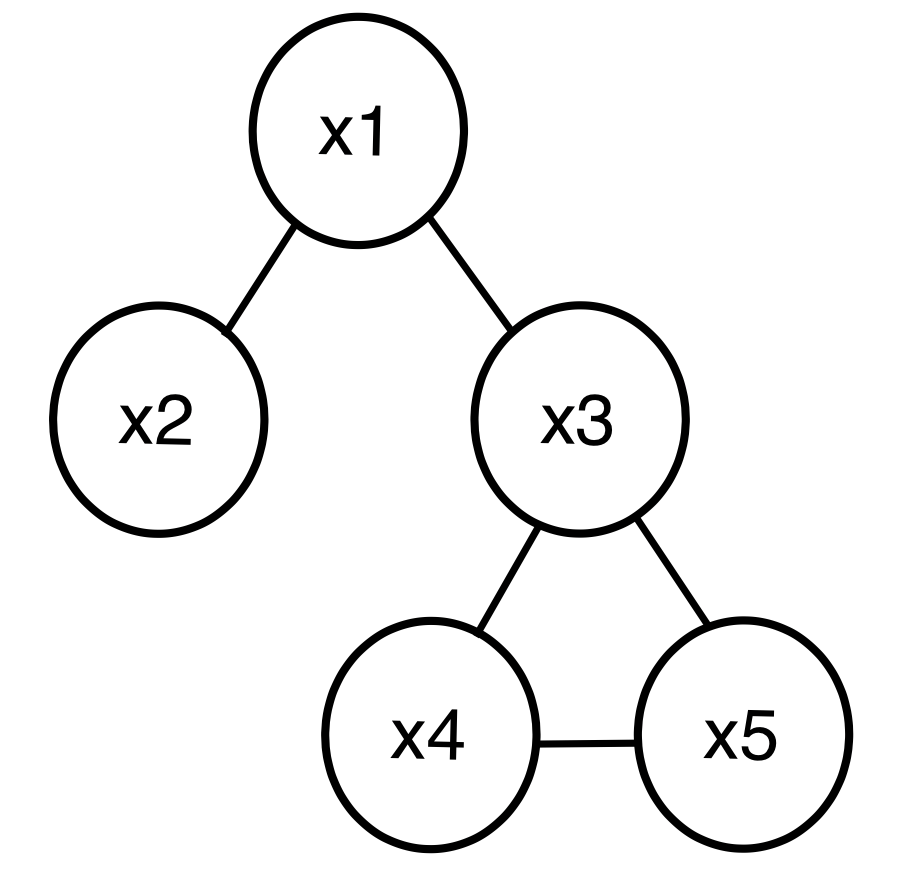
위 그림과 같이 방향성이 없는 graphical model을 말한다.
특징
- xi, xj 사이에 edge가 존재한다면, 'ij' edge를 제외한 어떠한 값들이 주어져도 xi와xj는 독립적이지 않다.
- xi와 xj사이에 edge가 존재하지 않으면, 'ij' edge를 제외한 어떠한 값들이 주어져도 xi와 xj는 독립이다.
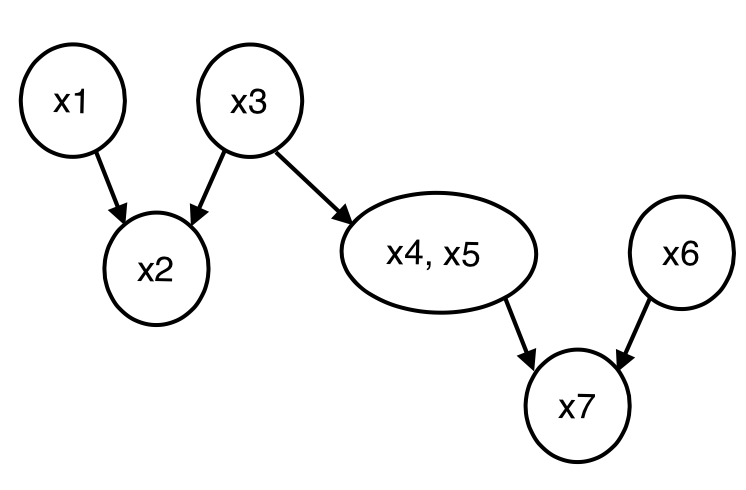
위 예시를 통해 특징을 살펴보면 x2,x4,x5가 주어져도 x1과 x3이 direct로 연결되어있기 때문에 독립이 아니다.
반대로 x1과 x5는 독립이 아니지만, x3이 주어지는 순간 이어지지 않았기 때문에 독립이 된다.
노드 사이의 edge는 potential function으로 표현할 수 있다.
위 그래프로 예시를 들면
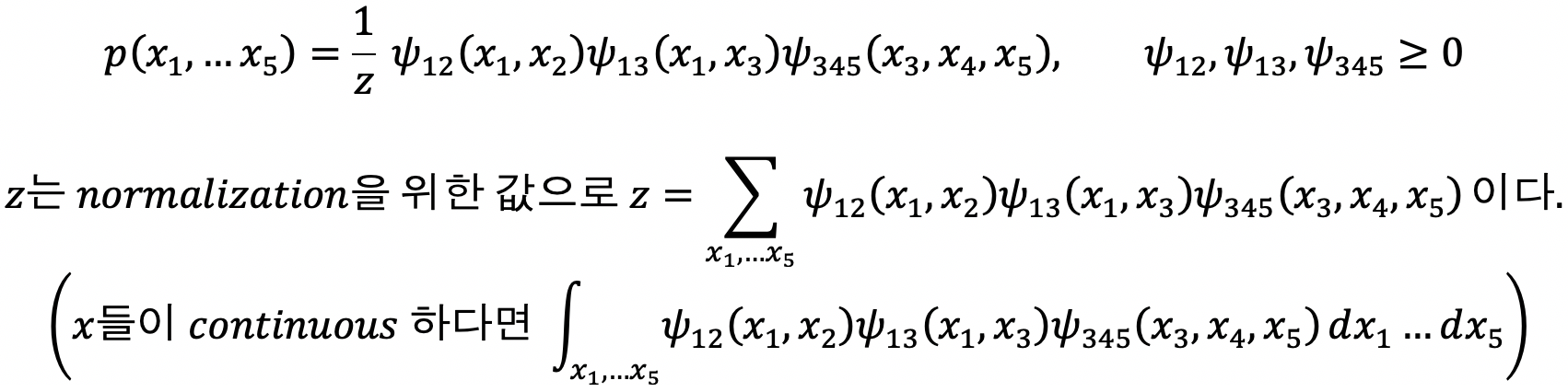
즉, 그래프로부터 나올 수 있는 모든 independency를 가지는 distribution의 전체 set(식으로 부터 나타나는 distribution의 set) 를 나타낼 수 있다.
이때, 모든 엣지에 대해서 노드가 있는 경우를 clique라 하는데, 노드 사이의 연결된 edge가 가장 많은 clique가 maximal clique가 된다.
위 그림에선, (x1,x2),(x1,x3),(x3,x4,x5) 3개의 clique가 있고, 이중 maximal clique는 (x3,x4,x5)이다.
확률 구하는 방법
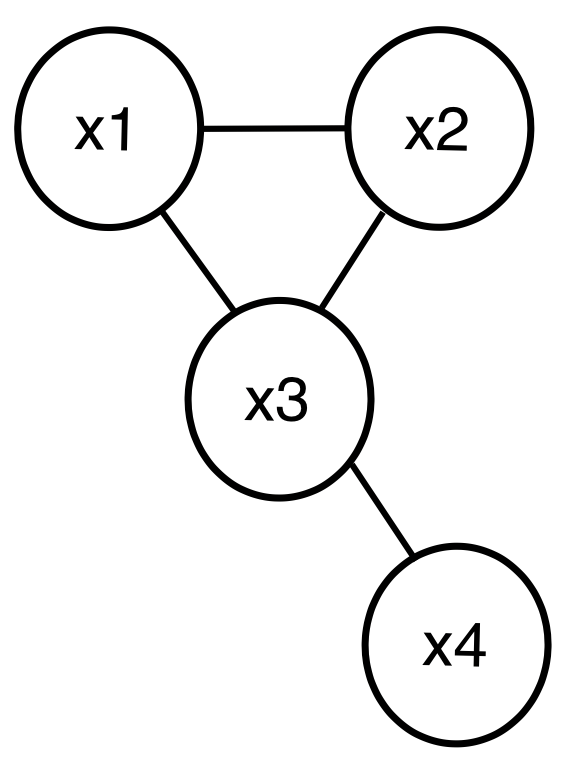
다음과 같은 undirected graphical model이 있고, {x1,x2,x3.x4} ∈ {0,1}4 라고 하자. 이를 바탕으로 표를 그려보면
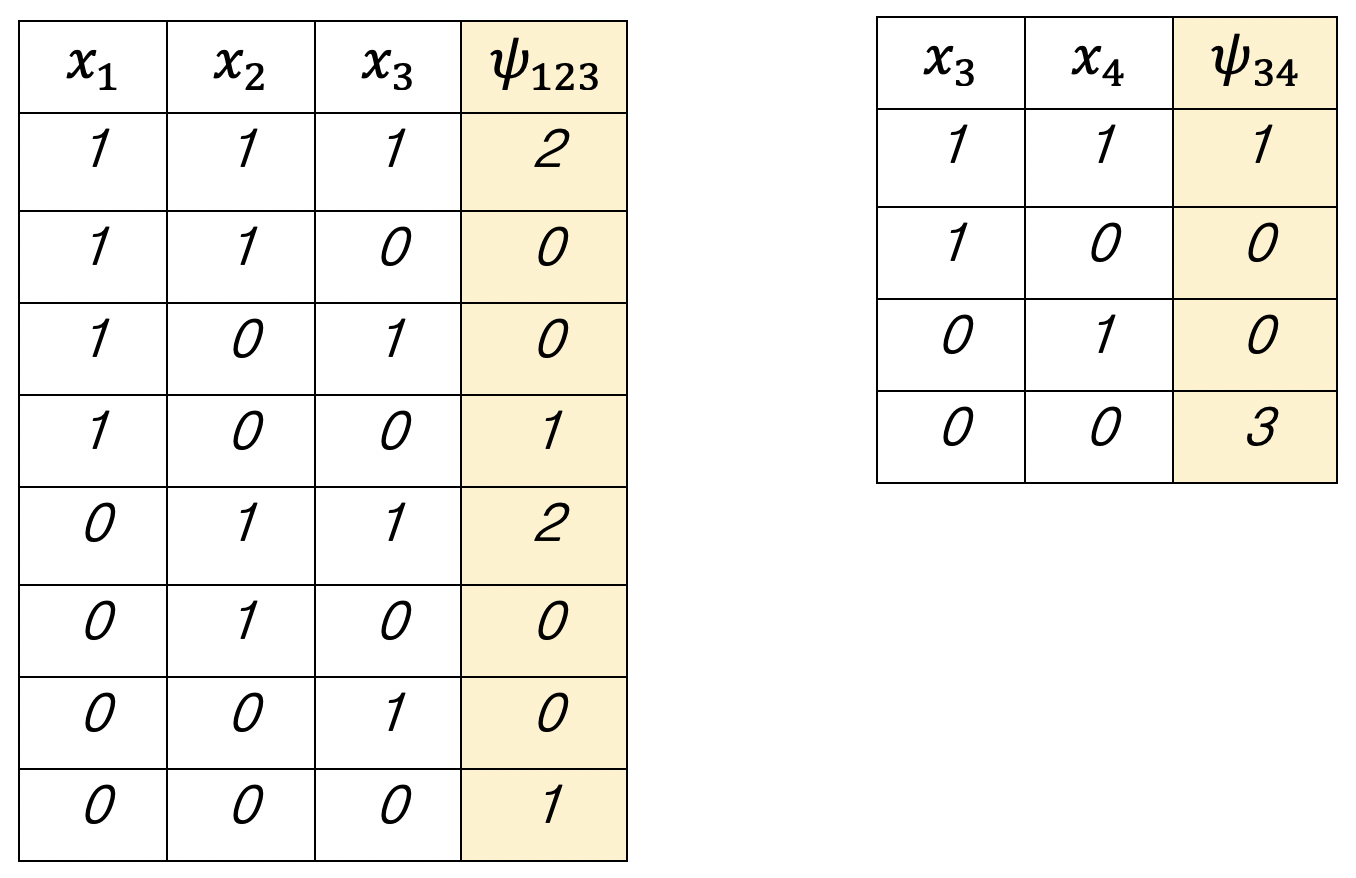
이때, potential function은 non negative값으로 임의로 잡은 것이다. 표를 참고하면

위 표에 따르면 우리는 p(x1,x2,x3,x4)의 모든 값을 estimation하기 위해선 총 12개의 parameter가 필요하다.
반대로, 이런 graphical model을 사용하지 않는다면 x1,x2,x3,x4 모든 경우에 대해 값을 구해줘야된다.
(ex. x1,x2,x3,x4 = 1,1,1,1 일 때, p(1,1,1,1) = m1111/N)
이렇게 총 24-1=15개의 parameter를 estimation 해주어야 된다. (마지막 p는 1-(15번까지 구한 p의 합) 이므로 estimation 할 필요가 없기 때문에 1을 빼준다.)
이렇듯 graphical model을 사용하면 estimation 해야 될 parameter의 수를 줄일 수 있다.
conditional indepency일때 확률
위 예시와 같은 그래프에서 x3=1로 주어졌다고 가정해보자.
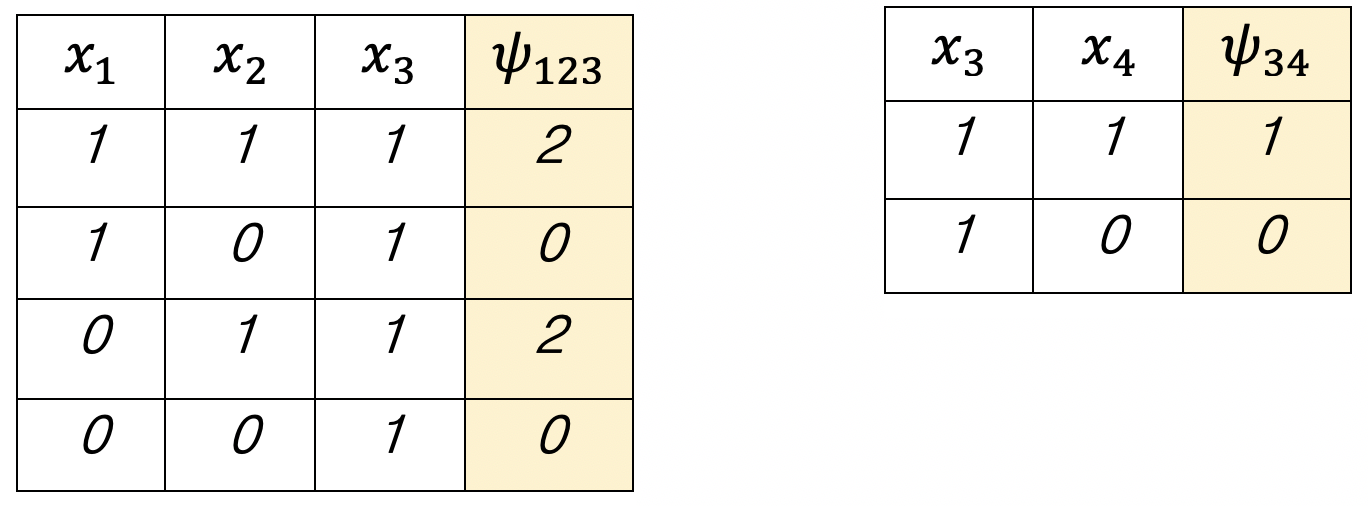
표를 참고로 예시들을 구해보면
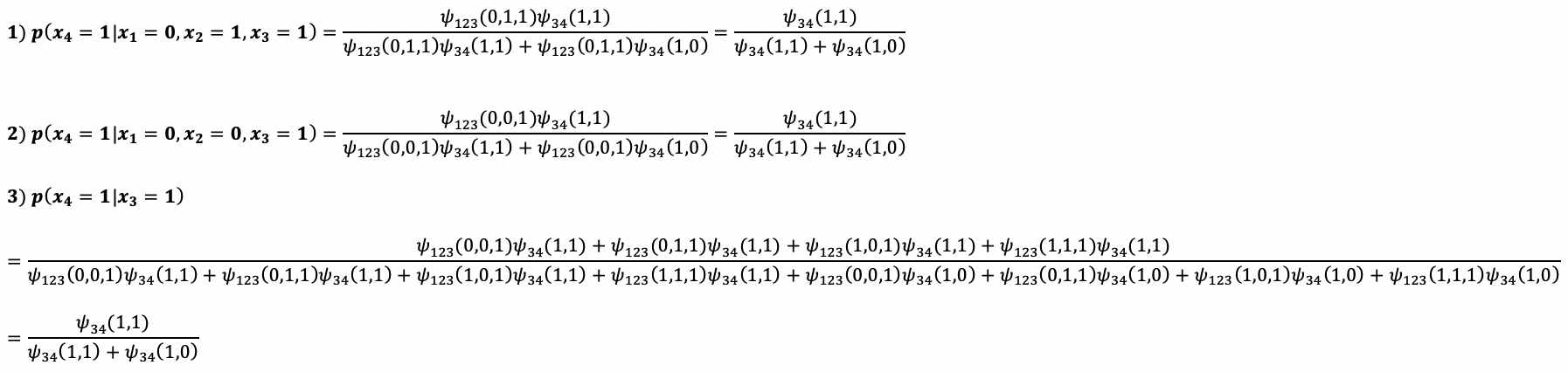
이때, p의 결과값들이 모두 같다는 것을 알 수 있다. 1번식과 2번식을 비교해보면 x2의 값이 변해도 p값이 변하지 않았으므로, x3이 특정 값으로 주어졌다면 x2와 x4가 서로 독립이라는 것을 알 수 있다.(x2값이 변해도 x4를 구하기 위한 확률이 변함이 없다)
Multinomial distribution(다항분포)
여러 번의 독립적 시행에서 각각의 값이 특정 횟수가 나타날 확률을 정의한다.(ex. 주사위 던지기, 동전 던지기)
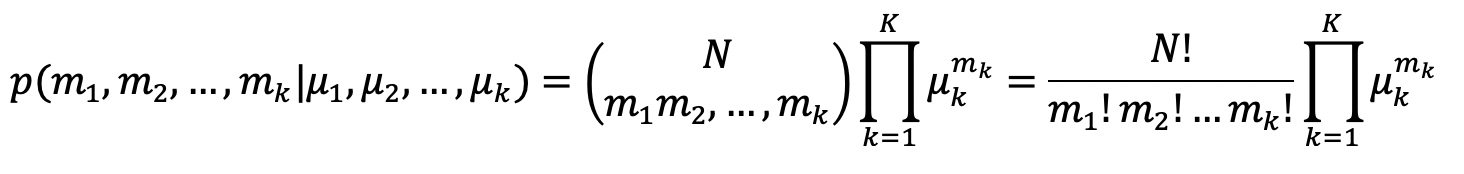
어떤 시행에서 k가지의 값이 나타날 수 있을 때, 총 K번의 시행을 한다.
m : 각 독립 시행별로 각 사건이 발생 한 횟수
μ : 각 독립 시행별로 각 사건이 발생 할 확률
데이터 m값들이 주어졌을 때, 파라미터 μ를 구하는 방법 -> maximum likelihood 방법을 사용한다. maximum likelihood(최대 가능도) 방법은 어떤 parameter가 주어졌을 때, 원하는 값들이 나올 가능도를 최대로 만드는 parameter를 선택하는 방법이다.
p(m1...mk|μ1,...,μk) 함수가 liklihood function이 되므로 maximum이 되는 값을 찾기 위해 함수를 미분해준다.
미분값이 0이 되도록 하여 값을 구하면
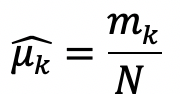
다음과 같은 optimal 함수를 얻을 수 있다. 즉, 개수의 비율을 가지고 확률을 estimation할 수 있다는 것이다.
예를들어 주사위를 100번 던지고 1인 면이 30번 나왔다고 가정하자. maximum likelihood estimation을 사용하여 1인 면이 나올 확률을 구해보면 mk/N 이므로 30/100 = 3/10 의 확률로 1이 나온다는 얘기가 된다.
Learning
위 directed model과 undirected 모델의 learning 을 maximum likelihood로 한다면
direct graphical model은, 각 local probability distribution에 대해서만 estimation 하면 된다. 반면, undirect graphical model은, 전체 parameter를 한꺼번에 estimation 해야된다.(parameter가 clique마다 estimation 되지 않는다)
Leranin을 할 때는 model을 direct, undirect 중 어떤 것을 사용하는지, data가 discrete한지 continuous 한지에 따라 총 4가지 상황으로 분류할 수 있다.
1. directed model 과 discrete data.
{x1,x2,x3} ∈ {0,1}3 인 데이터가 있고, p(x1,x2 | x3)을 estimation 하고 싶다면
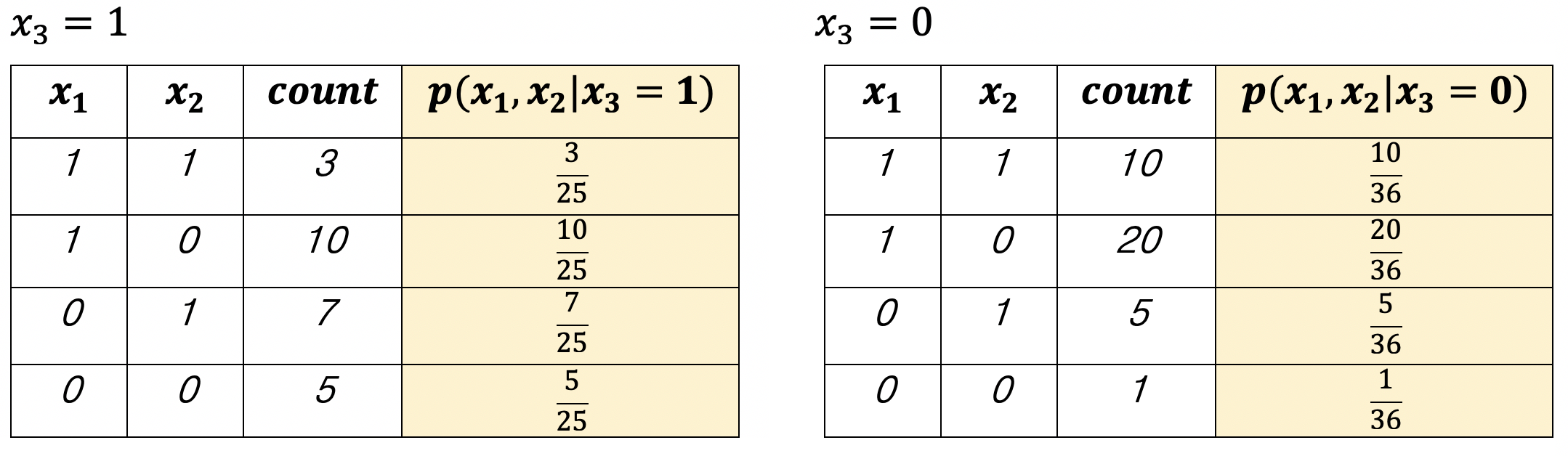
다음과 같이 x3가 특정한 값을 가지는 데이터만 모아 표를 만들어서 estimation 할 수 있다.
count는 해당 데이터가 나온 횟수를 counting했다는 의미이고, 위 표에서 해당 값들은 계산을 위해 임의로 잡은 것이다.
2. directed model 과 continuous data
1번 처럼 p(x1,x2 | x3)를 구하는데, 이 joint probability density function이 가우시안이라 가정한다.
p(x1,x2 | x3)의 mean과 variance를 구하기 위해선 p(x1,x2,x3)의 mean과 variance를 우선적으로 구해야된다.

3. undirected model 과 discrete data
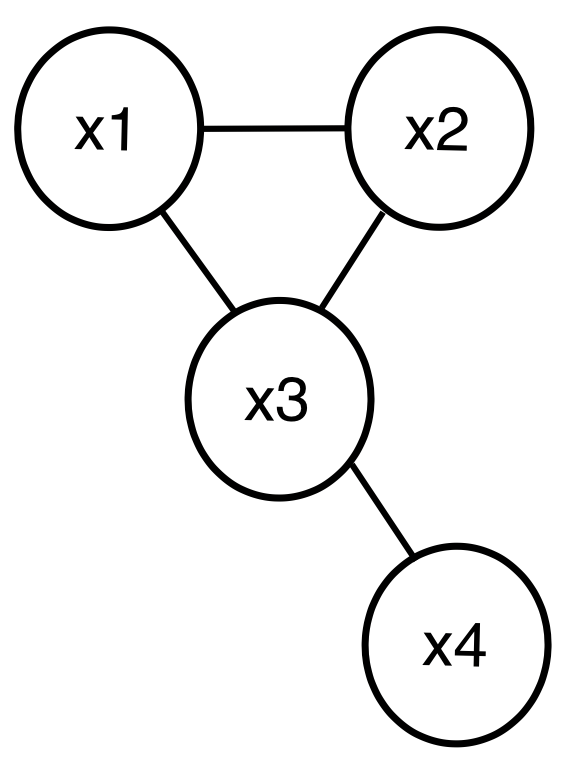
다음과 같은 {x1,x2,x3,x4} ∈ {0,1}3인 undirected graphical model이 있다고 할 때,

이때 N은 총 데이터 수를 말한다.
위와같은 식 12개를 구할 수 있으므로, 12개의 식을 통해서 모든 프사이와 파이 값 들을 구해낼 수 있다.
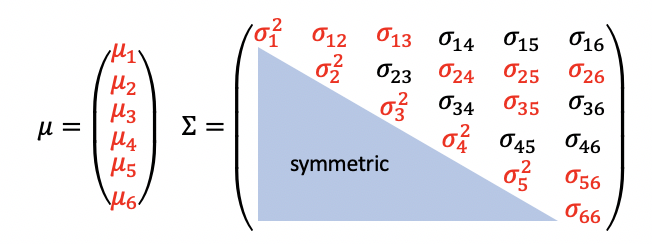
4. undirected model 과 continuous data
joint density function p(x|μ,Σ)가 가우시안이라 할 때
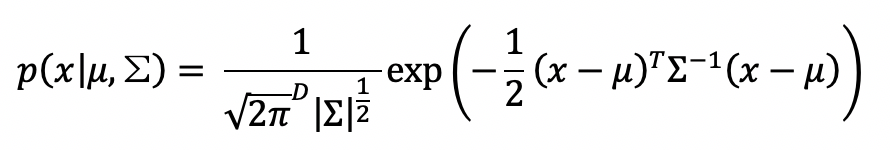
다음과 같이 볼 수 있다. 이때 ∑-1ij가 0이면 xi와 xj node가 서로 연결되지 않았다는 의미이므로,
Λ = ∑-1로두고 식을 전개 후 maximum likelihood를 위해 미분해준다.
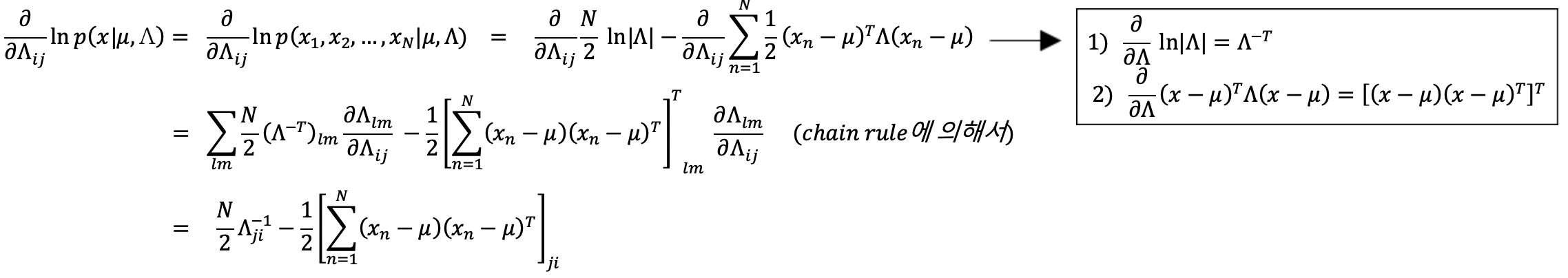
xl과 xm 사이에 edge가 존재하지 않는 경우 Λlm=0으로 두고 gradient ascent 해서 maximum likelihood를 수행할 수 있다.
'학교수업정리 > 인공지능' 카테고리의 다른 글
| [인공지능] probability model and parameter estimation (0) | 2020.11.27 |
|---|---|
| [인공지능] cover's theorem, Kernel methods (1) | 2020.11.24 |
| [인공지능] Optimization with constraint, Large margin methods (0) | 2020.10.14 |
| [인공지능] Nearest neighbor methods(이웃 알고리즘), KNN (2) | 2020.10.09 |
| [인공지능] Perceptron Convergence theorem (0) | 2020.10.06 |



